
[dataWhale] 电力系统预测
本文代码基本都参考自 joyful_pandas
赛题及要求
task 1
基本代码
1 | # 1. 导入需要用到的相关库 |
数据展示
1 | >>> print(train[:5]) |
具体函数及语法
1. 索引
相应代码:train[train['dt']<=20]
train['dt']返回的是一个 series 数据类型,即 dt 这一列的数据(故没有column列名),并从中筛选出11-20天的数据 target ,最后又转换为 DataFrame 的格式。
1 | >>> print(train['dt'][:5]) |
1 | >>> print((train['dt']<=20)[:5]) |
1 | >>> print(train[train['dt']<=20][:5]) |
2. 分组
相应代码:train[train['dt']<=20].groupby(['id'])['target'].mean()
原型: df.groupby(分组依据)[数据来源].使用操作
表示的是将一个 id 下的所有 target 求平均。id代表一个具体的房子,它11-20天每天都有不同的电力消耗 target,对其求平均,最后的结果是每一行都是不同的 id 及其 target_mean。
可以看到,最后的结果是没有索引的!只有id,没有target的列名
1 | >>> train_demo = train[train['dt']<=20] |
3. 重置索引
df.set_index()表示将某一列的数据都当作索引。可以加append=true保留原本的列索引。df.reset_index(['id'], drop=true)即是 set 的逆函数,表示取消某一列索引,drop=true表示直接把这一列删除,不恢复到数据中。df.reset_index() 表示重置所有索引,且生成一个默认的索引。
1 | >>> target_mean = train[train['dt']<=20].groupby(['id'])['target'].mean().reset_index() |
4. 合并 merge()
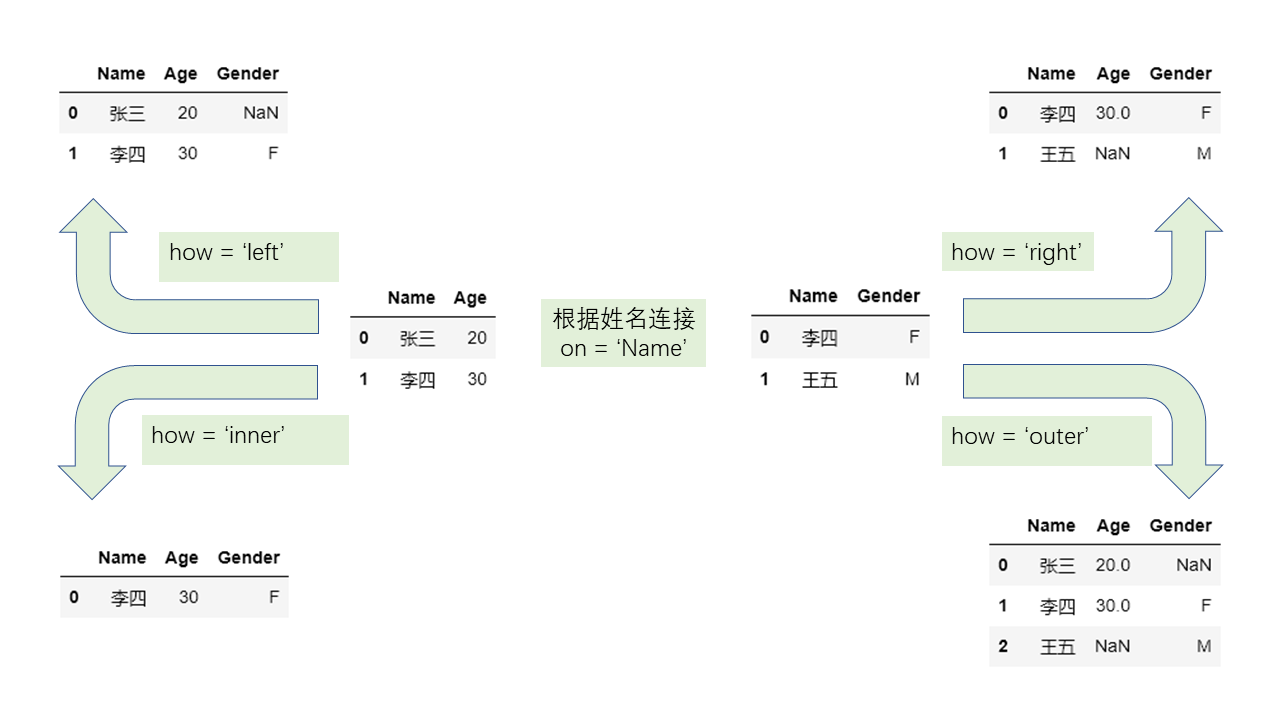
相应代码:test = test.merge(target_mean, on=['id'], how='left')
on=['id']表示按 id 这一列进行数据的合并。how='left'表示只保存与 test 测试集有的 id 相关的数据。- 如果列的名字不相同,则还有
left_on='',right_on=''的表示
1 | >>> print(test[:5]) |
注意到,我们前十天每天预测的target是相同的,这也是我们task1的算法,即用11-20天消耗的平均值作为我们预测近10天的结果。
5. 保存
test[['id','dt','target']].to_csv('submit.csv', index=None)
- 保存
['id','dt','target']三列数据到文件 submit.csv。 index=None表示不保存索引,因为我们excel表格自带有索引。
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 yolo乌啼霜满天!